The Algorithmic Apothecary
How biopharma R&D can industrialize learning with AI, closed-loop evidence, back-translation, and regulator-defensible governance.
How to industrialize R&D velocity without breaking regulatory trust.
BioPharma R&D in the era of generative biology
For most of modern pharma history, R&D has operated like a high-end craft shop: brilliant specialists, hard-won intuition, and a long chain of experiments that slowly convert biological uncertainty into therapeutic confidence.
Although historically effective, this artisan model is rapidly approaching its limit. Hard-won intuition remains the spark, but it lacks the scale to process the explosive complexity of modern biological data in the era of generative biology.
In 2026, the winners will be the organizations that can industrialize learning to enable faster hypotheses, faster tests, faster kill decisions, and faster evidence, while doing all of this in a way that is regulator-defensible.
That is what the Algorithmic Apothecary represents: an R&D system where AI does not merely accelerate isolated tasks, but re-architects the entire loop from disease insight to therapeutic design to market authorization, while raising the bar on governance, credibility, and traceability.
Executive summary
Each R&D step can be optimized through AI, but true advantage comes from a closed learning loop that back-translates clinical ground truth to continuously retrain the discovery engine.
Value is primarily driven by discovery speed, meaning the patent tail, and clinical quality, meaning higher probability of success. Crucially, early efficiency gains from automation partially subsidize the initial structural investments, softening the classical investment J-curve.
Tools are commodities, but governance is the moat. The ability to prove an AI’s decision under audit is the difference between a prototype and a product.
Adopt a value-gated roadmap where funding for higher-risk biological modeling is released only as the organization captures hard-dollar savings from lower-risk operational automation.
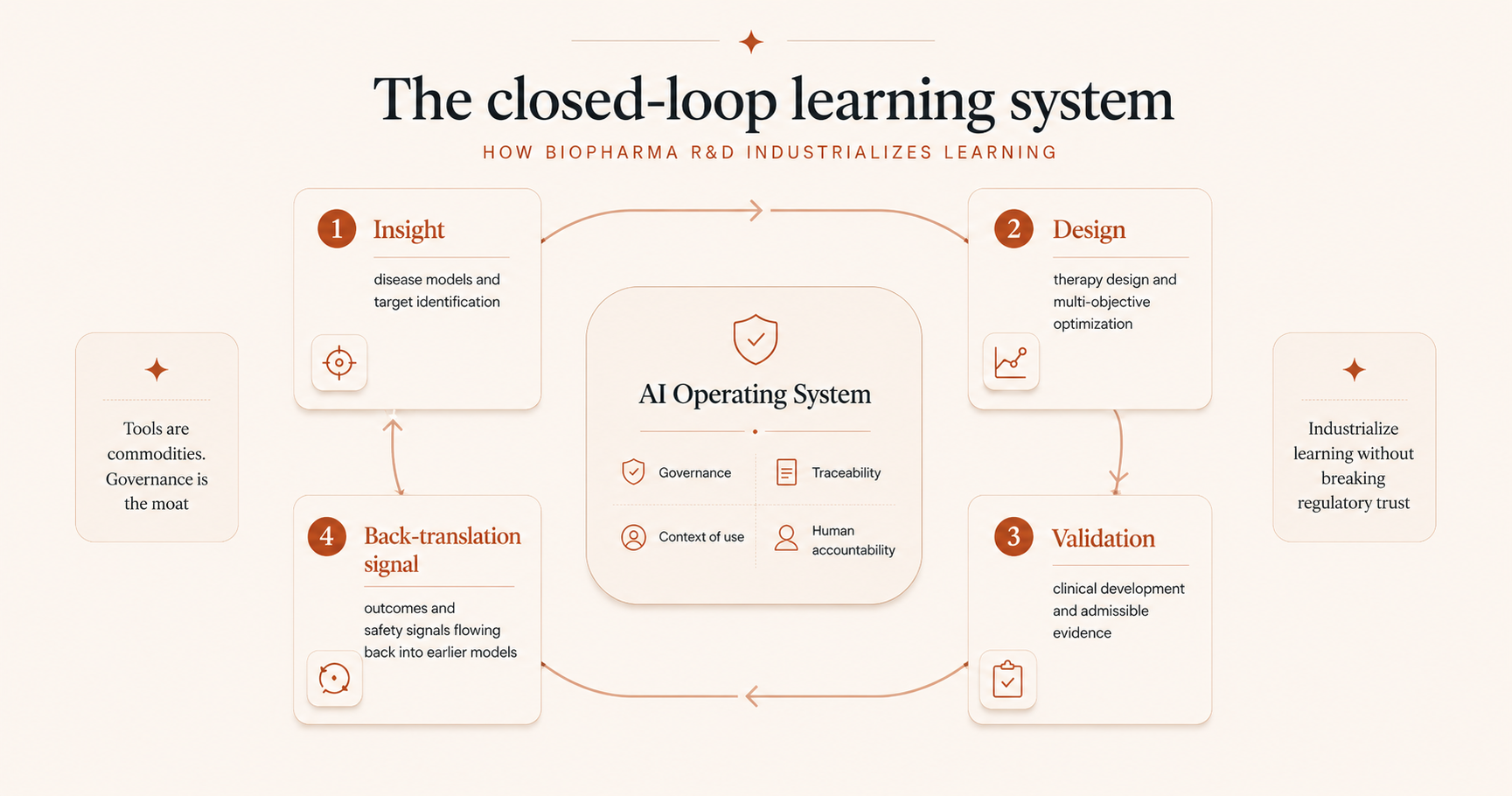
The linear R&D process is becoming a closed-loop learning system
A practical way to see the transformation is to view the R&D process not as a linear flow, but as a cycle where late-stage data retrains early-stage models:
- Insight: develop disease models and identify targets.
- Design: engineer therapies that address those targets.
- Validation: execute trials to obtain admissible evidence.
- The back-translation signal: clinical outcomes and safety signals must flow back to inform previous steps. This is how advantage compounds.
Historically, this loop was broken by time. A failure in Year 5 rarely taught the Discovery team in Year 1.
In a learning system, a toxicity signal or non-responder dataset in the clinic immediately becomes a negative prompt or training weight for the discovery engine, systematically preventing the same mistake on the next asset.
The strategic implication is stark: AI does not remove risk. It compresses the timeline over which risk reveals itself.
That is both the foundation of competitive advantage and the source of new failure modes.
Step 1: From target hunting to systems-level disease understanding
Target discovery has always been constrained by two bottlenecks: incomplete disease models and human bandwidth to integrate evidence.
AI changes that by integrating diverse data modalities and surfacing patterns that are hard to see with traditional approaches.
What changes in practice
Multi-omics and genetics become a target nomination engine. Instead of one modality driving a hypothesis, AI integrates genomics, transcriptomics, proteomics, metabolomics, epigenomics, and increasingly single-cell and spatial data. Network analyses broaden the target universe, shifting pipelines away from herd behavior around familiar proteins.
Phenotypic discovery comes back at scale. High-content imaging plus deep learning enables cell-first target discovery. By learning phenotypic fingerprints from perturbations and compound exposures, AI can work backward from cellular rescue to the genes and pathways that matter, especially where genetics is ambiguous or animal models are weak.
In silico experimentation narrows the hypothesis space before wet-lab validation. AI paired with CRISPR screens, iPSC-derived disease models, organoids, and simulation can reduce the number of physical experiments needed to get to a credible shortlist. This does not replace biology. It makes biology more targeted.
Knowledge integration becomes an evidence synthesis capability. Knowledge graphs and LLM-based literature mining connect genes, pathways, phenotypes, drugs, and trial histories, surfacing non-obvious links, repurposing hypotheses, and reducing time from question to evidence-backed shortlist.
What is fragile, and why
Provenance and explainability debt. Multi-modal integration is powerful, but without lineage and rationale, you generate targets that look great in a deck and die in translation.
Validation throughput becomes the constraint. The bottleneck shifts from ideation to confirming causality quickly enough to kill weak targets early. If your wet lab validation capacity cannot scale to match your computational output, you create a dangerous backlog.
If the AI is a firehose, the wet lab is a straw.
Step 2: Therapy design becomes multi-objective engineering, not linear optimization
Once a target is chosen, the historical model was sequential: generate candidates, optimize potency, then deal with ADMET, then scramble for translation, only to finally worry about manufacturability.
AI breaks that sequence by enabling multi-objective optimization earlier and compressing the search space across modalities.
What changes in practice
Modality selection becomes computationally disciplined. AI and knowledge graphs help teams become explicit about whether a target is best addressed by small molecules, antibodies, degraders, RNA modulation, gene editing, or cell therapies, based on localization, expression, tractability, safety priors, and precedent. The key is not that AI chooses. It forces clarity on assumptions, constraints, and trade-offs.
Candidate generation expands dramatically, then immediately becomes a governance problem. Generative chemistry and protein design can increase candidate hypotheses per unit time. Without constraints, you get the pretty molecule problem: synthetically infeasible, unstable, or non-developable candidates that create false momentum.
Optimization becomes Pareto management across potency, selectivity, ADMET, and safety. The strategic shift is away from single-metric heroics, such as potency at all costs, to portfolio-grade decisioning: candidates that are good enough across everything rather than exceptional in one dimension and fatal in another.
Translation gets pulled upstream as a design requirement. Linking target engagement to biomarkers to predicted clinical response, often via PK/PD and MIDD integration, pushes human plausibility earlier. The benefit is fewer downstream surprises. The risk is building confidence on models that are not traceable or robust.
CMC and manufacturability become part of design, not downstream cleanup. Digital twins, predictive control, and soft sensors can shift CMC from a late-stage scramble to a design constraint, especially in biologics where variability is expensive. This creates advantage only when implemented within validated, GxP-aligned patterns.
What is fragile, and why
Candidate explosion without execution capacity. If generative AI suggests 1,000 molecules but your lab can synthesize only 10, you create a backlog, not speed. The bottleneck shifts from ideas to physical proof.
The paper tiger trap. Optimizing for predicted properties, such as predicted solubility, without frequent ground-truth loops leads to candidates that score perfectly in the model but fail instantly in the beaker.
Step 3: Clinical development shifts from execution to admissible evidence production
Clinical trials are where biology meets regulation, operations, and credibility.
AI’s biggest opportunity in Step 3 is not automation. It is reducing decision latency across feasibility, protocol design, recruitment, RBQM, analysis, and submission, all while meeting emerging expectations for AI credibility, traceability, and lifecycle control.
What changes in practice
Trial strategy becomes feasibility-first and auditable. AI and evidence synthesis increasingly force quantitative answers: can we recruit, will endpoints mature, and can we operationalize the study in real sites? Real-world data can inform event-rate assumptions and line-of-therapy selection, and in bounded contexts may support external control approaches, but only with disciplined documentation and context of use.
Protocol design becomes complexity engineering. AI supports scenario simulation to reduce visit burden, simplify schedules, and minimize dropout risk. It can detect internal inconsistencies early. The goal is not just maximal statistical power. It is implementability with traceability, aligned to modern quality-by-design expectations.
Recruitment becomes a data and workflow problem. AI-driven cohort identification using EHR, claims, and RWD can improve yield, but phenotype fidelity is the limiting factor. Messy data can swamp AI precision. Hybrid and decentralized models can expand access, but they can also create new friction if patient experience and site burden are not engineered.
RBQM and centralized monitoring become table stakes, and a closed-loop advantage. ML-based anomaly detection and data quality checks can reduce query volume and accelerate cleaning. But credibility, validation, change control, and drift monitoring are non-negotiable, especially as decentralized modalities increase data volume and messiness.
Submission readiness becomes a traceability contest. AI can accelerate document QC and consistency checks across protocol, SAP, and CSR, but the differentiator is your ability to answer: what AI was used, with what data, what version, under what context of use, with what monitoring, and under what change-control discipline? That posture is increasingly explicit in regulatory guidance and good practice principles.
What is fragile, and why
The black-box safety trap. Using AI to autonomously adjudicate safety signals or classify adverse events without human review creates significant risk. Regulators demand human accountability for patient safety. If you cannot explain why a specific heart event was classified as unrelated, meaning traceability, the entire dataset becomes inadmissible.
Data indigestion. Turning on the firehose of decentralized data, such as wearables, sensors, and home visits, without the cleaning infrastructure to handle it creates risk. High-frequency sensor data is notoriously noisy. Without robust, automated anomaly detection through RBQM, you risk drowning your valid efficacy signal in a swamp of operational noise.
The return signal: turning clinical data into an asset
The most expensive data in your organization is clinical trial data.
In the artisan model, this data has a single use: regulatory submission. Once the Clinical Study Report, or CSR, is filed, the data effectively dies in a PDF.
In the Algorithmic Apothecary, clinical data also serves as a valuable training asset for the next generation of discovery models.
This back-translation is the mechanism that allows the system to get smarter over time and compound proprietary advantage.
What changes in practice
Clinical failures become negative prompts for Discovery. When a molecule fails for unexpected toxicity or lack of efficacy, that data does not just sit in a safety database. It is immediately vectorized and fed back into the Discovery and Design models as a penalty function. The system learns: do not suggest this chemical scaffold again, or this target is invalid in this specific patient phenotype.
Biomarkers validate the digital twin. Actual patient response data is compared against the initial in silico predictions, meaning the digital twin of the patient used in design. The difference between predicted response and actual response is used to calibrate the disease models, reducing the error rate for the next program.
Operational data optimizes future protocols. It is not just biological data that loops back. Operational data, including site performance, recruitment rates, and query volume, feeds back into protocol design simulation. If a specific inclusion criterion caused a six-month delay in Trial A, the system flags it as a high-friction constraint when designing Trial B.
What is fragile, and why
The PDF wall. Most clinical data is locked in unstructured formats such as PDFs and SAS datasets that discovery algorithms cannot read.
The silo gap. Discovery scientists and clinical operations leaders rarely share the same data infrastructure. You cannot back-translate if your systems do not speak the same language.
CEO implications
Traceability becomes paramount. If you cannot show why a target was nominated, and what evidence would falsify it, you risk scaling noise by generating errors at industrial speed.
Your competitive edge becomes enforcing constraints early: design to developability and design to manufacturability from day one.
You are building an admissible evidence factory. AI value is realized only if it is packaged with traceable evidence chains and governed lifecycle controls. Think of RBQM as an operating system where differentiation will come from how quickly you close the loop: detection to triage to CAPA to prevention through SOP and process updates.
Treat clinical data as a dual-use asset: evidence for today's submission and training data for tomorrow's pipeline. While submission is the immediate commercial imperative, failing to recycle that data into your models is a massive waste of capital. If your clinical results, positive or negative, are not back-translated to update your discovery models within 90 days of database lock, you are paying full tuition for a lesson you are not learning.
The real differentiator: the AI Operating System
Competitors can buy the same tools you can. They cannot easily replicate your AI Operating System, the invisible layer of governance that turns tools into a compounding engine. To build a moat, you must enforce five mandates across the organization:
1. Data as a product, not a lake
Stop dumping data into swamps. Treat critical domain data as a product with explicit owners, SLAs, and, crucially, audit-ready lineage.
CEO question: can we trace every AI output back to the specific source records that produced it?
2. Credibility via context of use
Adopt a strict no context of use, no deployment rule. Every model influencing a regulated decision must have a defined context of use and a validation dossier tracking its performance limits and drift.
3. Human accountability, not just automation
Define clear decision rights. When the AI and the expert disagree, who breaks the tie? Who signs the report? Accountability must be explicit, or the system will stall in ambiguity.
4. Reproducibility by default
Enforce version control for the entire pipeline: data, code, and model weights. If you cannot reproduce a result from six months ago, you have a liability.
5. Operationalized ethics
Move beyond high-level principles. Implement specific operational controls for bias, privacy, and dual-use risks. In 2026, this is your license to operate.
The golden rule: own the brain, rent the muscle
Building this operating system clarifies the build versus partner dilemma. Since the operating system is your source of compounding advantage, meaning your moat, you cannot outsource it to a vendor.
You must own the brain: your data products, your governance artifacts, and your decision workflows. These are the assets that get smarter over time.
You can rent the muscle: foundation models, commodity tooling, and generic implementation capacity. These are depreciating assets that everyone has access to.
The economic case: speed, cost, and the J-curve
Why take on the pain of this transformation?
The business case rests on three hard levers.
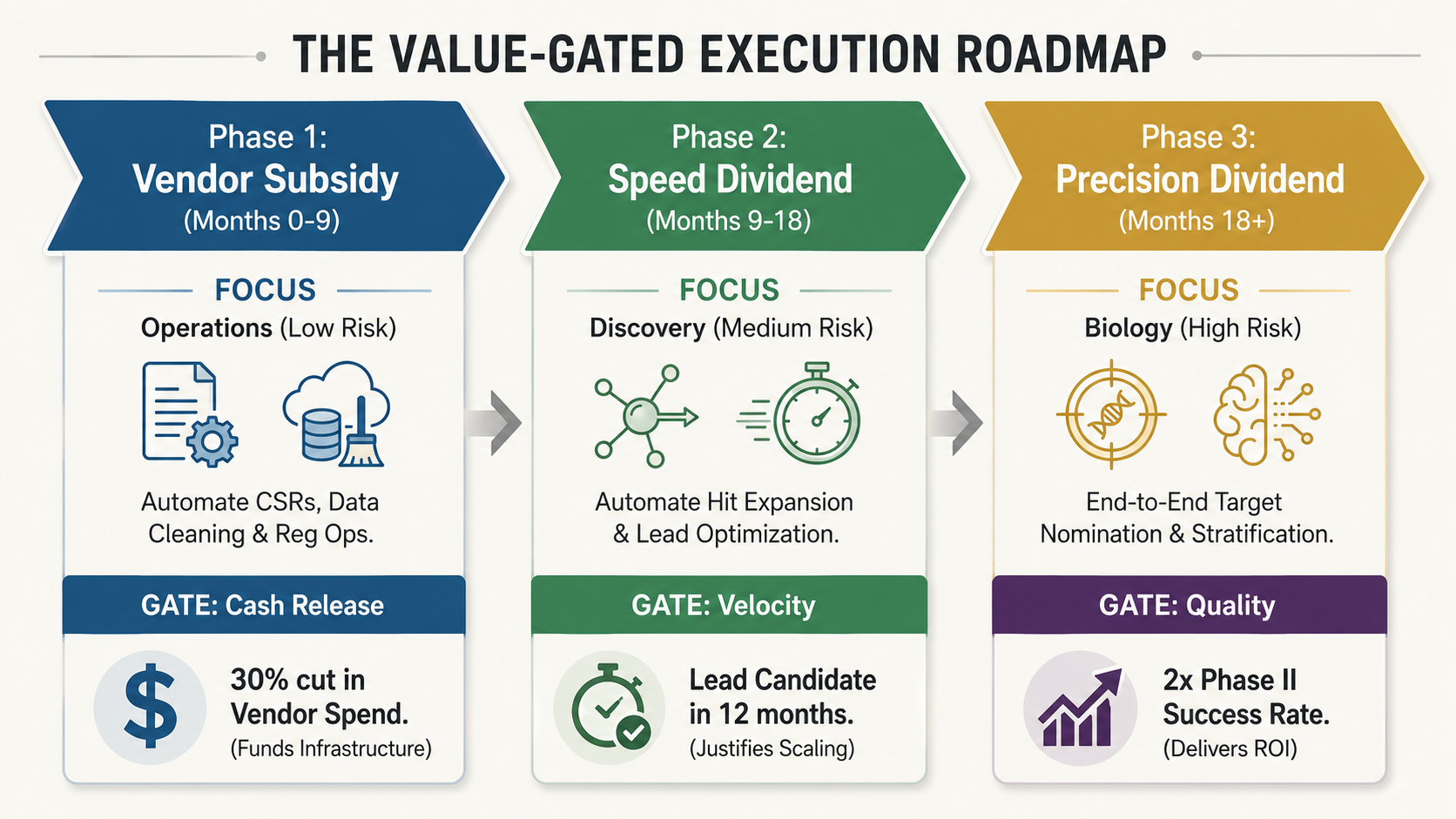
1. The discovery dividend, or time impact
Compress the Target to IND time by more than two years through multiparameter optimization. Instead of fixing potency in Year 1, then fixing toxicity in Year 2, then fixing solubility in Year 3, the AI solves all three constraints simultaneously in the design phase. You add more than two years of patent life to the commercial tail of the asset, in addition to the benefit of having more of the early market to yourself.
2. The quality premium, or probability-of-success impact
Increase probability of success by 50% for Phase II trials due to better inputs, such as patient-derived data through iPSC and causal targets through CRISPR, that dramatically reduce the rate of efficacy failures in Phase II. This effectively doubles the productivity of every R&D dollar without increasing the budget.
3. The efficiency floor, or operational impact
Drive a 30% to 40% reduction in administrative overhead, including medical writing, data cleaning, and regulatory publishing, through AI agents. Unlike the scientific gains, these savings appear in Year 1. They provide the efficiency floor that de-risks the program and subsidizes the compute costs for the scientific work.
The ROI for this transformation follows a classic J-curve.
In Year 1, costs will rise and velocity may dip. You are paying a data tax as you invest in engineering, clean legacy datasets, and establish governance. However, because we activate the efficiency lever immediately, we soften the dip. The operational savings fund the scientific transition, preventing the program from becoming a pure cost center during the build phase. The lion’s share of the ROI arrives in Years 2 and 3, when the negative prompts begin to bite. The system starts killing weak ideas before they enter the wet lab, and the cost per candidate collapses.
The execution strategy: a value-gated roadmap
The destination is ambitious, but the path cannot be a blank check.
A board in 2026 has no appetite for another Digital Transformation 2.0 with an exploding budget and rubbery timelines. A value-gated roadmap de-risks the investment by treating the transformation as a portfolio, releasing funding for high-risk scientific innovation only as the organization captures hard savings from low-risk operational efficiency.
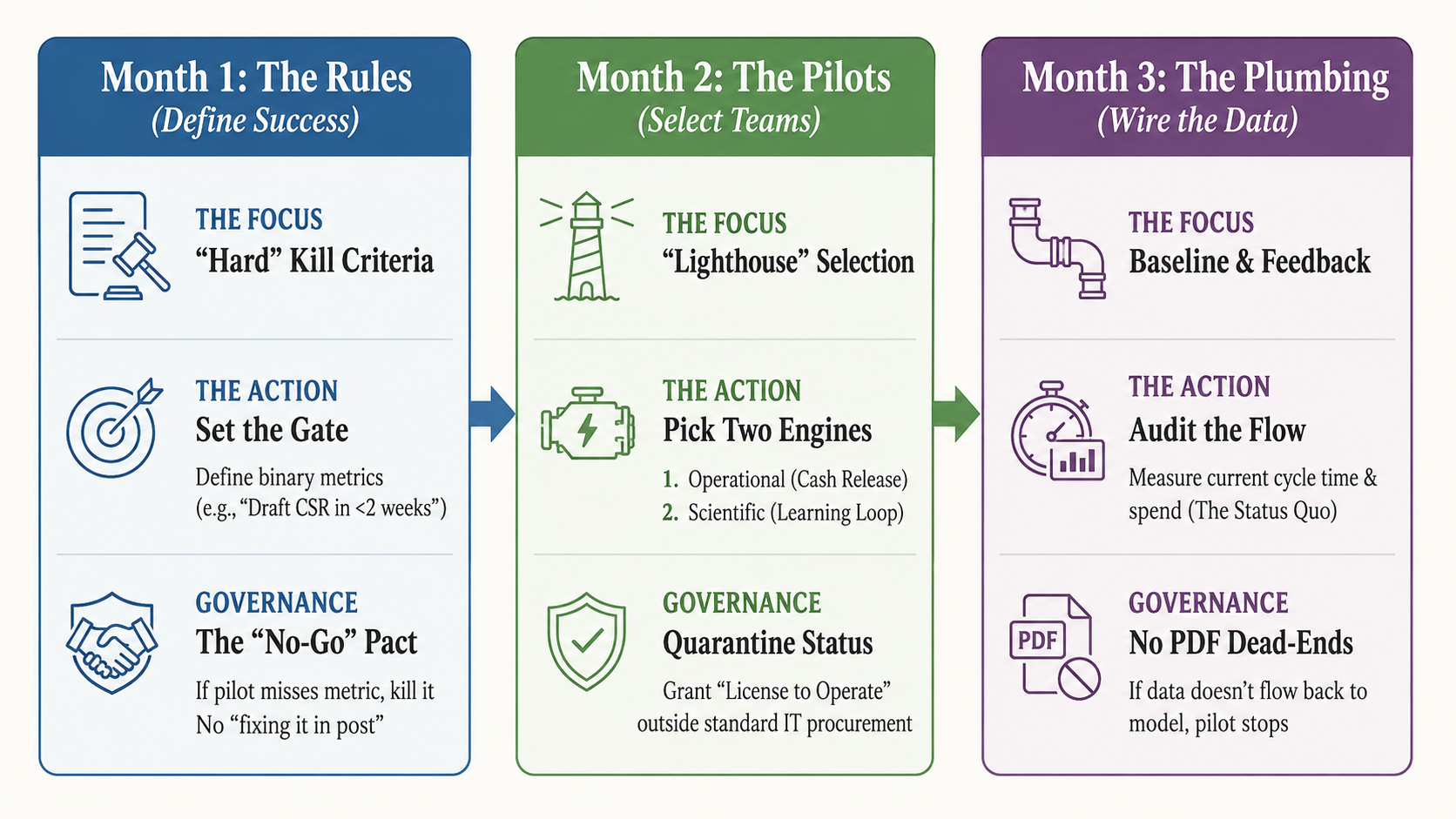
The 90-day mobilization plan: governance over gadgets
The first 90 days should establish the governance required to run this portfolio, focus investment on the highest-value work, and build enough organizational momentum to make the transformation real.
Executive scoreboard: six metrics that reveal whether AI is compounding
If AI is a real strategic advantage in your R&D engine, it will show up in a small set of measurable outputs:
- Loop time, meaning signal to decision to action to learning, in discovery and clinical operations.
- Early kill rate, meaning programs terminated before expensive inflection points.
- Assay throughput and cycle time, meaning whether wet lab can keep up with hypothesis generation.
- Protocol amendment rate, because complexity is a speed tax.
- Query volume and time to clean, meaning RBQM effectiveness and operational friction.
- Model lifecycle readiness, meaning context of use defined, validation dossier complete, and drift monitoring active.
Instrument these metrics early in the transformation. Without them, you risk mistaking motion for progress.
Closing: the Algorithmic Apothecary is a leadership choice
AI can make life sciences R&D faster and more valuable by compressing the distance between hypothesis and evidence. But speed without governance is only acceleration toward the next wall.
The difference between strategic advantage and high-velocity chaos is the operating system around the model.
CEO imperative: judge AI by the learning system it creates, not by the demo performance of the model.
The winner in 2030 will be the company that industrializes the loop between the lab, the clinic, and the code.
Glossary of terms
ADMET, Absorption, Distribution, Metabolism, Excretion, Toxicity
The standard criteria for evaluating a drug’s viability. In the Algorithmic Apothecary, the key shift is using AI to predict toxicity during the design phase, rather than waiting for animal testing.
Back-translation
The process of feeding late-stage data, such as clinical outcomes and safety signals, back into early-stage models. It turns clinical failure into a negative prompt that prevents the discovery engine from making the same mistake twice.
CAPA, Corrective and Preventive Action
A regulatory quality process used to fix errors, corrective action, and update systems to ensure they do not recur, preventive action. In an AI operating system, the speed of the CAPA loop is a key metric of organizational agility.
CMC, Chemistry, Manufacturing, and Controls
The detailed body of evidence proving a drug can be consistently manufactured, packaged, and stored safely. The article argues that CMC must shift from a late-stage scramble to an early-stage design constraint, preventing the design of molecules that are biologically potent but impossible to manufacture at scale.
Context of Use
A formal regulatory statement that defines exactly what an AI model is allowed to do, for example triage safety alerts, and what it is not allowed to do, for example diagnose patients. Without a defined context of use, an AI model is a prototype, not a deployable asset.
CRISPR screens
A high-throughput method using gene-editing technology to test thousands of genes simultaneously. It acts as a search engine for biology, identifying which genes actually drive a disease.
CSR, Clinical Study Report
The massive, formal document summarizing a clinical trial for regulators. It is often a PDF wall: unstructured data that is difficult for discovery algorithms to read or learn from.
Decentralized modalities
Clinical trial methods that collect data outside of a hospital, for example via wearable sensors, telemedicine, or home health visits. They increase patient access but generate massive amounts of noisy data that requires AI cleaning.
Degraders, PROTACs and molecular glues
A class of drugs that tag a disease-causing protein for destruction by the cell’s own waste disposal system, rather than just blocking it. AI is essential for designing their complex three-way geometry.
Hit expansion
A discovery phase where scientists synthesize variations, or cousins, of a promising molecule, called a hit, to optimize its properties. It is a high-velocity loop ideal for testing AI predictions quickly.
IND, Investigational New Drug
The application filed with the FDA to request permission to test a new drug in humans, meaning Phase I clinical trials.
iPSC, induced pluripotent stem cells
Stem cells created by rewinding adult cells, such as skin or blood. They allow scientists to grow human disease tissues, such as Alzheimer’s neurons, in a lab dish, enabling patient-on-a-chip testing before human trials.
MIDD, Model-Informed Drug Development
The application of quantitative models and simulations to predict drug behavior and optimize dose selection. It is a regulatory-endorsed pathway that bridges the gap between lab data and human trials.
Negative prompt
A concept borrowed from generative AI. It refers to using specific data, such as a toxic molecule, to train a model on what not to generate. It turns failure data into a constraint for future designs.
PK/PD, Pharmacokinetics and Pharmacodynamics
The study of how a drug moves through the body, PK, and its biological effect, PD. Integrating PK/PD data into AI models through MIDD allows teams to simulate human dose responses early, reducing the risk of picking the wrong dose in clinical trials.
RBQM, Risk-Based Quality Management
A methodology that uses data analytics to identify quality risks in a clinical trial, such as data anomalies at a specific site, in real time, rather than checking all data manually.
SAP, Statistical Analysis Plan
The strictly binding rulebook written before a clinical trial ends, detailing exactly how the data will be analyzed. It prevents p-hacking, meaning manipulating data to find a positive result.